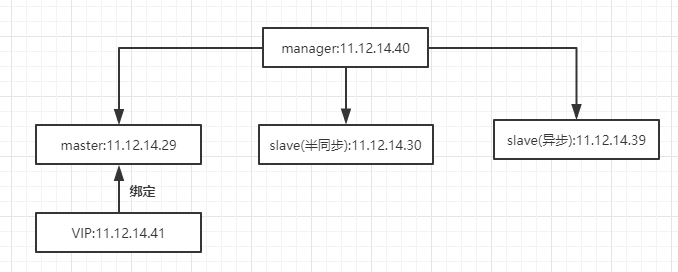
实验环境
此次实验的环境如下
-
MySQL 5.7.25
-
Redhat 6.10
-
操作系统账号:mysql
-
数据库复制账号:repl
-
复制格式:基于行的复制
-
MHA版本: 0.56
| IP地址 | 主从关系 | 复制账号 | 复制格式 |
|---|---|---|---|
| 11.12.14.29 | 主库 | repl | Row-Based |
| 11.12.14.30 | 从库(半同步/备master) | repl | Row-Based |
| 11.12.14.39 | 从库(异步) | repl | Row-Based |
| 11.12.14.40 | 管理节点 | 无 | 无 |
| 11.12.14.41 | VIP | 无 | 无 |
1 检查现有状态
我们可以先通过 show slave status\G查看从库同步是否正常
2 打开管理节点日志
我们通过如下命令事实查看切换过程
tail -f /etc/mha/manager/mha.log3.关闭主库
我们通过如下命令关闭主库
service mysqld stop4 日志分析
这时我们查看你管理阶段的日志输出
4.1 发现并检测主库状态
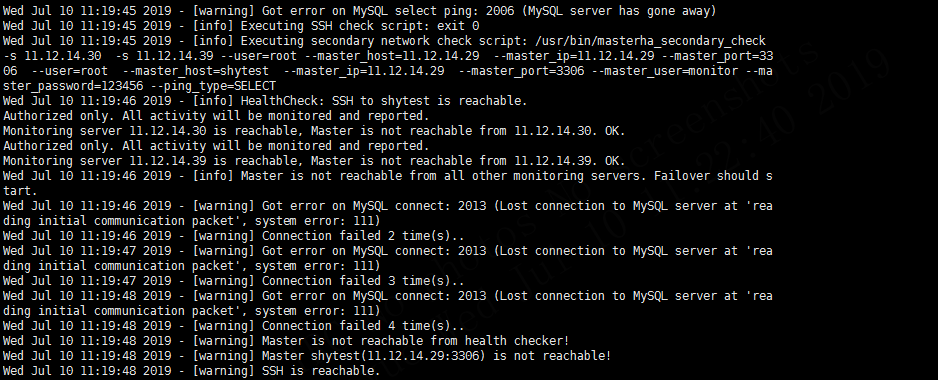
从上图可以看出,首先管理节点发现MySQL服务挂掉,之后调用masterha_secondary_check脚本分别从另外2个从库检查主库,发现也无法连接
4.2 重新检查所有服务器状态
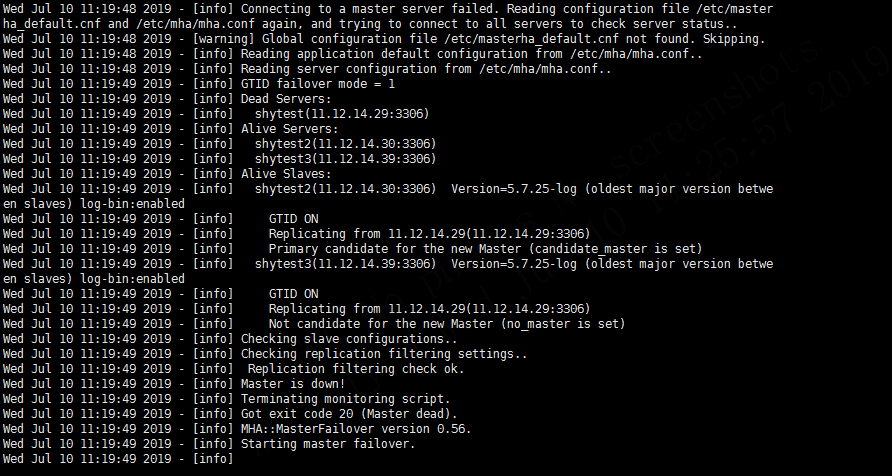
从上图可以看出,mha重新读取配置文件并确认数据库状态
- Dead Servers
- Alive Servers
4.3 failover第一阶段-配置文件确认
接下来进入master failover第一阶段-配置文件确认
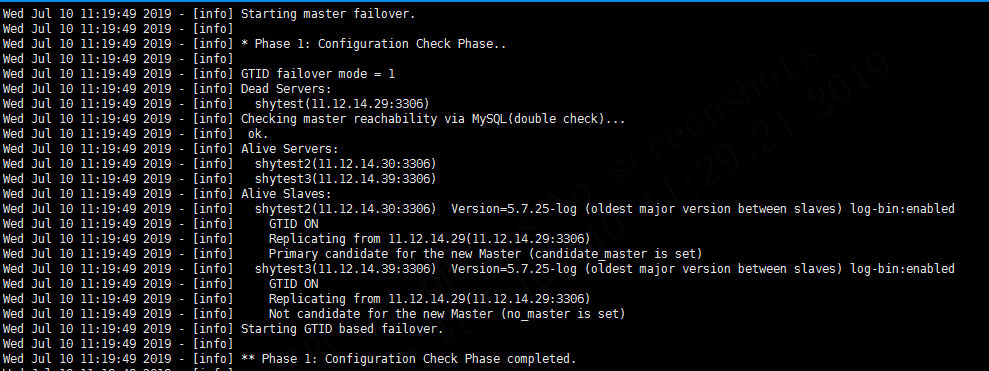
这里还是确认阶段
4.4 failover第二阶段-关闭主库

我没有定义shutdown_script,所以没有调用
4.5 failover第三阶段-主库恢复阶段
这个阶段分为如下几个部分
4.5.1 获取最新的slave
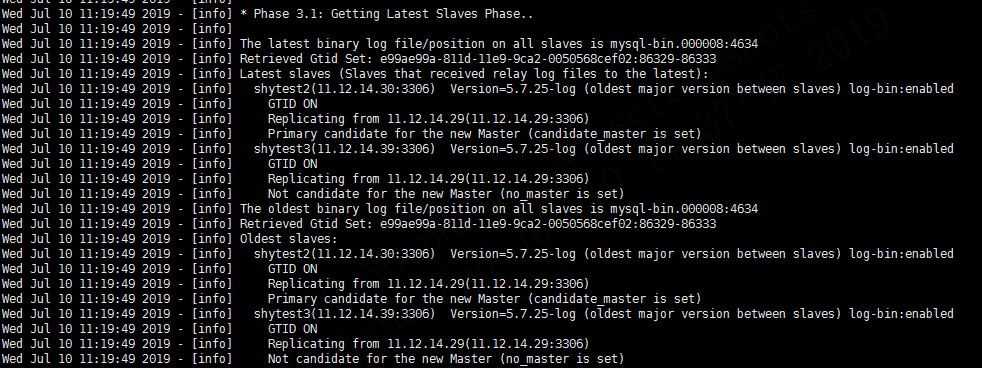
4.5.2 决定新的主库阶段
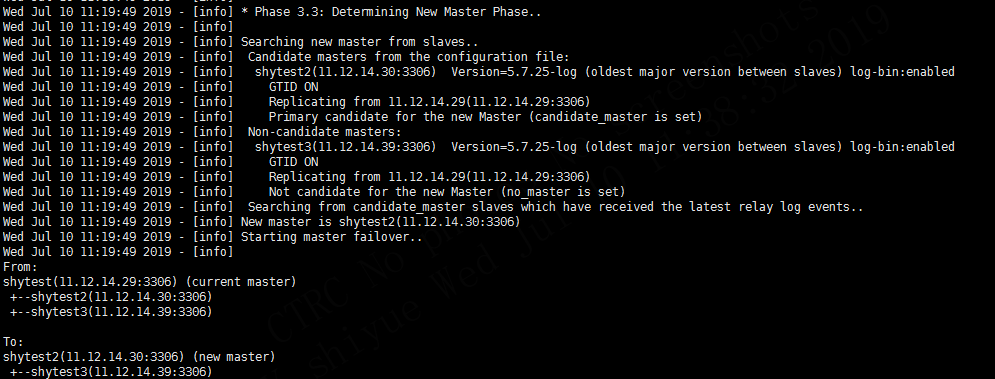
4.5.3 新主库恢复阶段
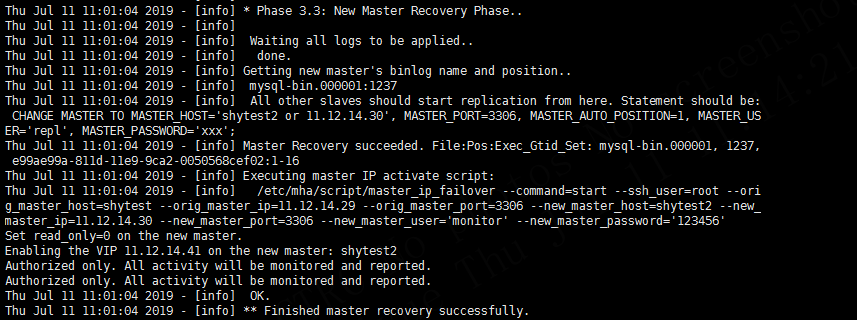
从上图可以看出首先应用日志,之后生成从库重新同步的语句,之后在新主库上启用VIP
4.6 failover第四阶段-从库恢复阶段
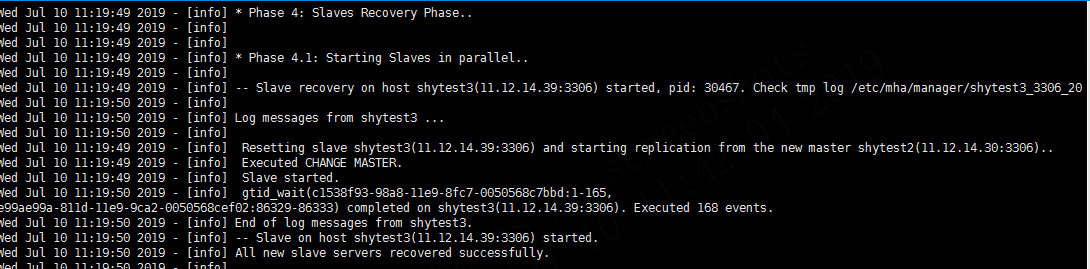
该阶段主要为将从库的同步指向新的主库,
这里需要注意的是,如果采用了基于二进制位置点的复制,如果从库启用了GTID,这时会自动采用GTID形式的复制而不是基于位置点的,即 show slave status\G 时auto_position为1
4.7 failover第五阶段:清理阶段

这一阶段首先将新的主库的slave信息清除
如果前面启动mha时加了--remove_dead_master_conf参数,则会将旧的主库的信息删除
4.8 failover报告
最后日志会打印failover过程的报告,如图
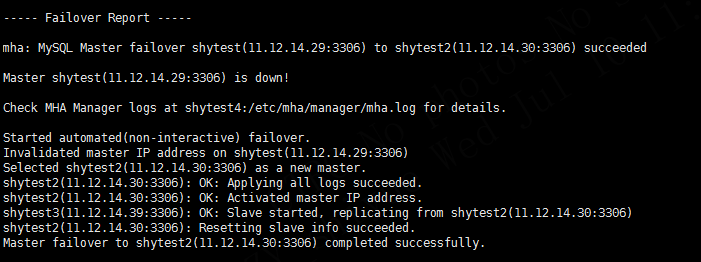
以上就是一个完整的failover过程,这时可以手动查看各节点信息
5. 注意事项
- 在完成failover后MHA进程会自动退出
- VIP会从旧的主库漂移到新的主库
- 如启用了GTID,从库的同步会自动切换到GTID模式
- 在做主从同步的时候建议清理下从库相关信息 reset master及reset slave all
- 新的主库会自动将read_only设为OFF
- failover完成后记得删除mha.failover.complete文件,否则再次启动后会发生故障会无法failover
- failover完成后,旧主库会从配置文件中删除
6. 参考资料
https://www.percona.com/blog/2016/09/02/mha-quickstart-guide/
http://www.ttlsa.com/mysql/step-one-by-one-deploy-mysql-mha-cluster/