前期回顾
前面我们介绍了MySQL Galera的相关内容
这期开始讲一个数据库分库分表中间件Mycat
该专题的理论内容我会参考官方的文档,最后实践部分会根据自己的环境
上节说了一些Mycat的一些概念
对应Mycat来说,其最主要的功能还是数据分片的规则,这节我们详细说下
1. 分片规则配置文件
上节我们在介绍Mycat概念的时候说了,我们在配置逻辑表时需要填写分片规则
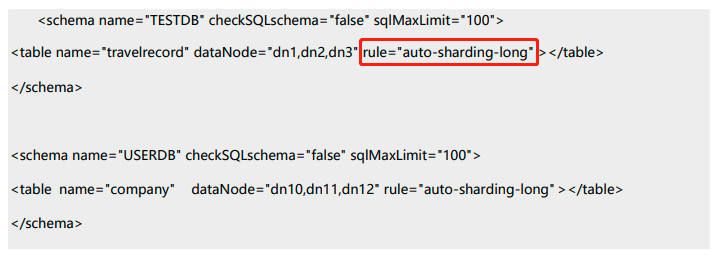
这里的rule名称即为分片规则的名称
我们通过rule.xml配置文件配置
该配置文件主要包含两个标签
- tableRule
- function
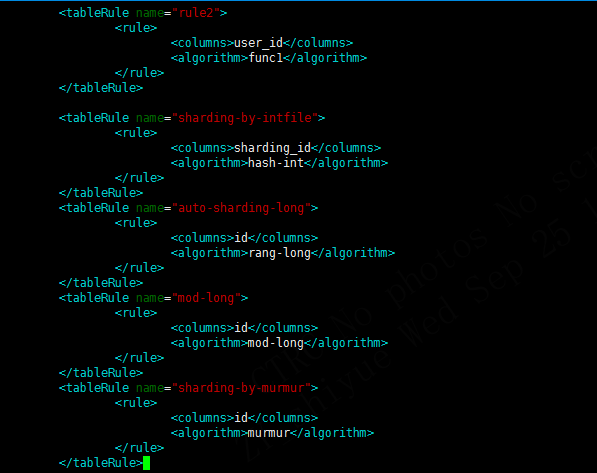
tableRule的name属性就是上面表的分片规则的名称
| 属性名称 | 含义 |
|---|---|
| name | 表分片规则名称 |
| columns | 代表用哪个字段进行分片 |
| algorithm | 代表该分片规则用的算法,对应function标签 |
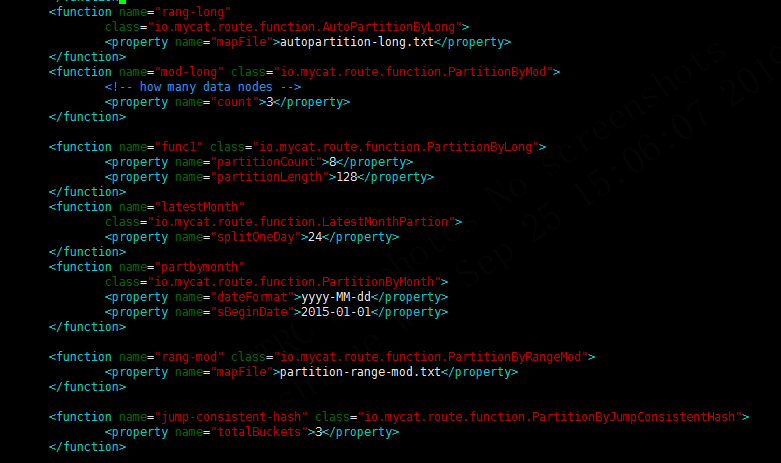
| 属性名称 | 含义 |
|---|---|
| name | 指定算法的名称 |
| class | 指定路由算法具体的类名字。 |
| algorithm | 具体算法需要用到的一些属性 |
从上面可以看出,我们可以新建新的分片规则对应Mycat提供的算法
2. Mycat常见分片规则
上面一节我们讲到分片规则依赖于算法,Mycat提供一些常用的算法,基本满足我们的需求,这里介绍几个,全部的请查看官方文档的10.5章节
2.1 分片枚举
通过在配置文件中配置可能的枚举 id,自己配置分片
本规则适用于特定的场景,比如有些业务需要按照省份或区县来做保存,而全国省份区县固定的,这类业务使用本条规则,配置如下
<tableRule name="sharding-by-intfile">
<rule>
<columns>user_id</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<function name="hash-int" class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
<property name="type">0</property>
<property name="defaultNode">0</property>
</function> partition-hash-init.txt
10000=0
10010=1
DEFAULT_NODE=1- columns 标识将要分片的表字段
- algorithm 分片函数名称
- mapFile 标识配置文件名称,type 默认值为0,0 表示 Integer,非零表示 String,所有的节点配置都是从0开始,即0代表节点 1
- defaultNode 默认节点:小于0表示不设置默认节点,大于等于0表示设置默认节点
默认节点
默认节点的作用:枚举分片时,如果碰到不识别的枚举值,就让它路由到默认节点 如果不配置默认节点,碰到不识别的枚举值就会报错 can’t find datanode for sharding column:column_nameval:ffffffff
2.2 范围约定
此分片适用于,提前规划好分片字段某个范围属于哪个分片
<tableRule name="auto-sharding-long">
<rule>
<columns>user_id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<function name="rang-long" class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
<property name="defaultNode">0</property>
</function>autopartition-long.txt
0-500M=0
500M-1000M=1
1000M-1500M=2 - columns 标识将要分片的表字段
- algorithm 分片函数名称
- mapFile代表配置文件路径
- defaultNode 超过范围后的默认节点,所有的节点配置都是从0开始,即0代表节点1
2.3 取模
此规则为对分片字段求模运算。
<tableRule name="mod-long">
<rule>
<columns>user_id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">3</property>
</function> - columns 标识将要分片的表字段
- algorithm 分片函数名称
- count属性请填写DN的数量
2.4 按日期(天)分片
此规则为按天分片。
<tableRule name="sharding-by-date">
<rule>
<columns>create_time</columns>
<algorithm>sharding-by-date</algorithm>
</rule>
</tableRule>
<function name="sharding-by-date" class="io.mycat.route.function.PartitionByDate">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2014-01-01</property>
<property name="sEndDate">2014-01-02</property>
<property name="sPartionDay">10</property>
</function> - columns 标识将要分片的表字段
- algorithm 分片函数名称
- dateFormat :日期格式
- sBeginDate :开始日期
- sEndDate:结束日期
- sPartionDay :分区天数,即默认从开始日期算起,分隔10天一个分区
如果配置了 sEndDate 则代表数据达到了这个日期的分片后循环从开始分片插入
2.5 应用指定
此规则是在运行阶段由应用自主决定路由到那个分片
<tableRule name="sharding-by-substring">
<rule>
<columns>user_id</columns>
<algorithm>sharding-by-substring</algorithm>
</rule>
</tableRule>
<function name="sharding-by-substring" class="io.mycat.route.function.PartitionDirectBySubString">
<property name="startIndex">0</property><!-- zero-based -->
<property name="size">2</property>
<property name="partitionCount">8</property>
<property name="defaultPartition">0</property>
</function>- columns 标识将要分片的表字段
- algorithm 分片函数名称
- partitionCount 分区的数量
- defaultPartition 默认分区
此方法为直接根据字符子串(必须是数字)计算分区号(由应用传递参数,显式指定分区号)。
例如 id=05-100000002
在此配置中代表根据 id 中从 startIndex=0,开始,截取 siz=2 位数字即 05,05 就是获取的分区,如果没传,默认分配到 defaultPartition
2.6 范围求模分片
先进行范围分片计算出分片组,组内再求模优点可以避免扩容时的数据迁移,又可以一定程度上避免范围分片的热点问题
综合了范围分片和求模分片的优点,分片组内使用求模可以保证组内数据比较均匀,分片组之间是范围分片可以兼顾范围查询。
最好事先规划好分片的数量,数据扩容时按分片组扩容,则原有分片组的数据不需要迁移。由于分片组内数据比较均匀,所以分片组内可以避免热点数据问题。
<tableRule name="auto-sharding-rang-mod">
<rule>
<columns>id</columns>
<algorithm>rang-mod</algorithm>
</rule>
</tableRule>
<function name="rang-mod" class="io.mycat.route.function.PartitionByRangeMod">
<property name="mapFile">partition-range-mod.txt</property>
<property name="defaultNode">21</property>
</function>- columns 标识将要分片的表字段
- algorithm 分片函数名称
- mapFile 代表配置文件路径
- defaultNode 超过范围后的默认节点顺序号,节点从 0 开始
partition-range-mod.txt
0-200M=5 //代表有 5 个分片节点
200M1-400M=1
400M1-600M=4
600M1-800M=4
800M1-1000M=6以上配置一个范围代表一个分片组,=号后面的数字代表该分片组所拥有的分片的数量。
2.7 日期范围hash分片
思想与范围求模一致,当由于日期在取模会有数据集中问题,所以改成 hash 方法。 先根据日期分组,再根据时间 hash 使得短期内数据分布的更均匀 优点可以避免扩容时的数据迁移,又可以一定程度上避免范围分片的热点问题 要求日期格式尽量精确些,不然达不到局部均匀的目的
<tableRule name="rangeDateHash">
<rule>
<columns>col_date</columns>
<algorithm>range-date-hash</algorithm>
</rule>
</tableRule>
<function name="range-date-hash" class="io.mycat.route.function.PartitionByRangeDateHash">
<property name="sBeginDate">2014-01-01 00:00:00</property>
<property name="sPartionDay">3</property>
<property name="dateFormat">yyyy-MM-dd HH:mm:ss</property>
<property name="groupPartionSize">6</property>
</function> - columns 标识将要分片的表字段
- algorithm 分片函数名称
- sPartionDay 代表多少天分一个分片
- groupPartionSize 代表分片组的大小
2.8 自然月分片
按月份列分区 ,每个自然月一个分片,格式 between 操作解析的范例。
<tableRule name="sharding-by-month">
<rule>
<columns>create_time</columns>
<algorithm>sharding-by-month</algorithm>
</rule>
</tableRule>
<function name="sharding-by-month"
class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2014-01-01</property>
</function> - columns 标识将要分片的表字段
- algorithm 分片函数名称
- dateFormat:日期字符串格式
- sBeginDate:开始日期